사실 인텔 비디오 칩셋들이나 드라이버가 좋은 평가를 받고 있는 것은 아닌지라 그래픽스 쪽으로는 그리 기대가 되지 않습니다만 CPU를 보조하는 가속기 개념으로 접근하면 활용성이 높을 것으로도 보입니다. 다만 기존의 GPU들이 GPGPU가 되면서 생기는 비슷한 효과에 비해 어느 정도 장점을 줄 것인지가 궁금해집니다. 인텔이 주장하는 것처럼 x86 개발 환경의 장점이 빛을 발할 것인지 기존 GPU에 비해 상대적으로 떨어지는 성능으로 사용자들에게 외면 받을지 지켜보는 게 너무 재밌을 것 같습니다. ^^
드디어 베일을 벗은 Intel의 CPU&GPU 하이브리드「Larrabee」
●DirectX 10 세대 GPU 것보다 CPU에 가까운 구조
Intel이 단위 시간당 처리량 프로세서「Larrabee (라라비)」의 개요를 공개했다.한마디로 말하면,Larrabee는 ,GPU와 CPU의 하이브리드이다.NVIDIA의 「G80(GeForce 8800」이후나 ,AMD(구ATI)의 「Radeon HD 2900(R600)」이후의 ,최신의 DirectX 10 세대 프로그램 가능 GPU와 비교하여도,Larrabee 쪽이 프로그램성이 더 크다.그래픽스 전용의 고정 기능 유닛도 구비하지만 ,NVIDIA나 AMD와 비교한다면 훨씬 비율이 작고,풀 프로그램 가능에 가까운 프로세서로 되어 있다.DirectX 10 세대 GPU보다 범용 컴퓨팅으로 접근한 것이 Larrabee이다.Intel은 우선 Larrabee를 그래픽스 지향 제품으로서 스타트한다.
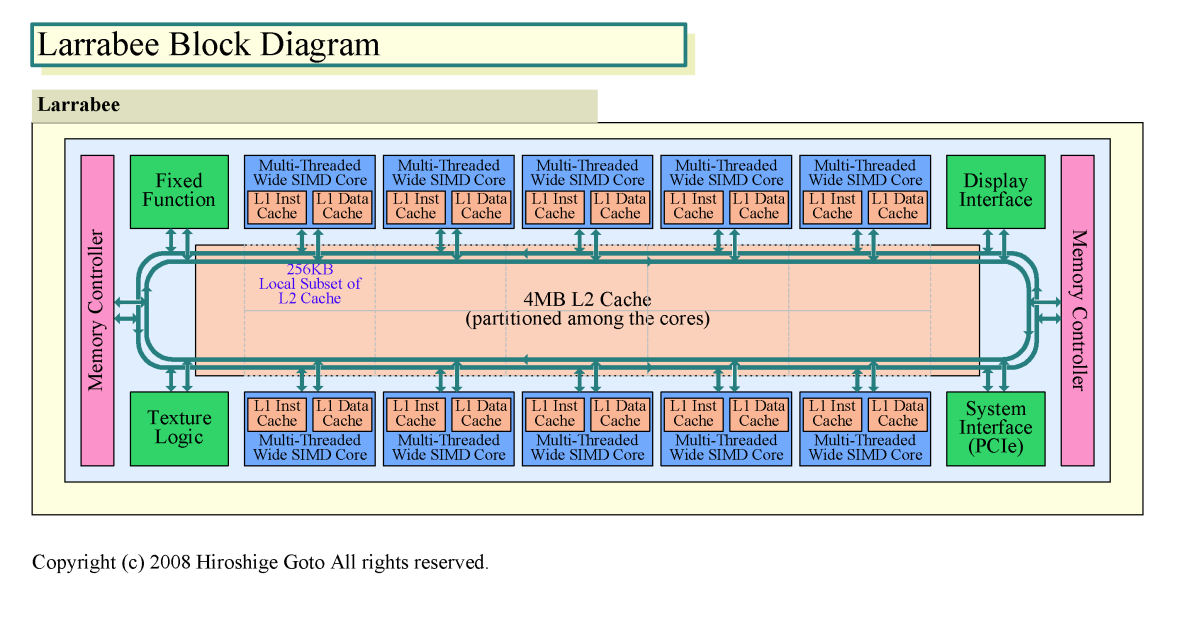
Larrabee는 ,10개의 x86 상위 상호 교환의 프로세서 코어를 탑재한다.각 프로세서 코어는 ,16-wide의 SIMD(Single Instruction, Multiple Data)구성의 벡터 연산 유닛을 구비한다.1 유닛으로 ,32-bit 단정밀도 부동 소수점 연산이라면,16개의 데이터에 대한 연산을 병렬에 1 클럭으로 행한 말을 할 수 있다.
CPU 코어는 인 오더 실행으로 ,2 명령 발행/클록.Intel은 ,Pentium에 준한다고 설명한다.단, Pentium에는 없는 와이드한 SIMD 유닛을 구비하고 하드웨어 멀티 스레드 기능이나 Fused Multiply Add(FMA),벡터 형의 프로세싱에 특화한 기능 등을 구비한다.
10개의 CPU 코어는 ,양방향의 고속 링 베이스에 접속하고 있다.베이스에는 10개의 프로세서 외,외부 인터페이스,메모리 컨트롤러,텍스쳐 유닛,그 밖의 고정 기능 유닛등이 접속하고 있다.또,4MB의 L2 캐시 메모리도 탑재되고 있고,각 프로세서 코어마다 파티션으로 구분되고 있다.
 |
| Larrabee의 블록 다이어그램 PDF 판은 여기 |
●32-bit 단정밀도로 16-wide의 와이드한 벡터 연산 유닛
캐시 계층은 2 계층으로 ,통합 L2 캐시 외에,각 프로세서에 32KB의 L1 명령 캐시와 32KB의 L1 데이터 캐시가 탑재되고 있다.Larrabee 전체로 ,캐시 코히어런시를 유지한다.또,L2 캐시에는 각 프로세서 코어가 서로 액세스할 수 있기 때문에 ,코어 사이의 데이터 교환이나 공유에 사용할 수 있다.NVIDIA도 AMD도 ,GPU의 프로세서 코어 사이로의 데이터 교환을 위해 소용량의 메모리를 구비하지만 ,GPU 전체에 걸치는 하드웨어로의 캐시 코히어런트 기구 등은 갖지 않는다.Larrabee는 ,현재의 프로그램 가능 GPU와 비교하여도,훨씬 CPU에 가까운 설계이다.
Larrabee의 프로세서 코어는 ,인 오더 실행으로 스칼라 유닛과 벡터 유닛의 2 실행 파이프를 구비한다.각각 전용의 스칼라 레지스터와 ,벡터 레지스터를 갖는다.CPU 코어는 ,L2 캐시중, 256KB의 로컬 서브셋(Local Subset)과 직접 연결되어 있다.프로세서 코어 사이의 커뮤니케이션은 ,링 베이스를 경유한다.
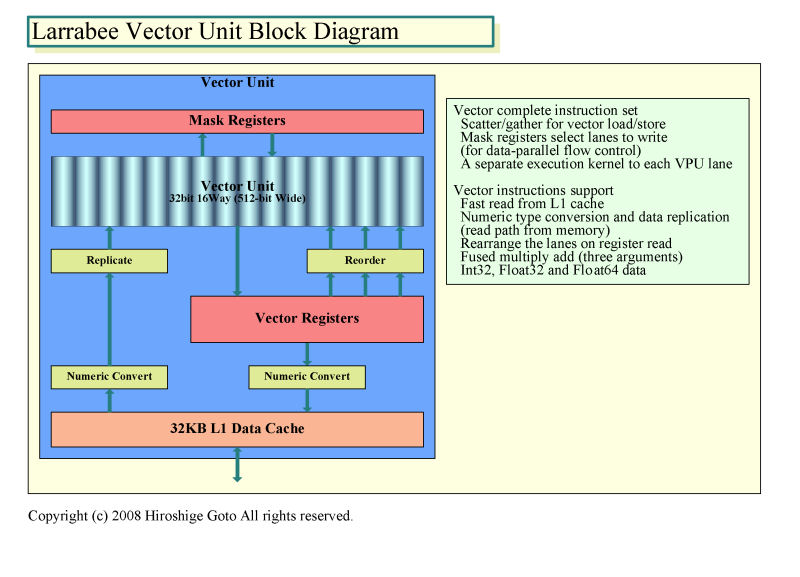
Larrabee 프로세서의 핵이라고 말할 수 있는 벡터 연산 유닛은 ,16-wide 구성으로 되어 있다.데이터 타입은 ,Int32(32-bit 정수),Float32(32-bit 부동 소수점),Float64(64-bit 부동 소수점)를 서포트한다.32-bit 때에 16-wide의 풀 단위 시간당 처리량으로 연산을 할 수 있다.벡터 프로세서에서는 ,연산한 각 데이터 요소의 각각으로 ,조건 분기에 의한 프로그램의 분기가 생긴 경우에 효율이 나쁘다.Larrabee로는 ,마스크 레지스터를 구비한 것으로 ,분기가 생긴 경우도 ,비교적 효율이 좋은 플로우 컨트롤이 가능해지도록 했다.이 기구는 ,NVIDIA의 G80/GT200계등이 구비하고 있는 기구와 비슷하다.
 |
| Larrabee 벡터 유닛의 블록 다이어그램 PDF 판은 여기 |
 |
| Larrabee x86 코어의 블록 다이어그램 PDF 판은 여기 |
●고정 하드웨어를 많이 줄인 프로그램 가능 프로세서
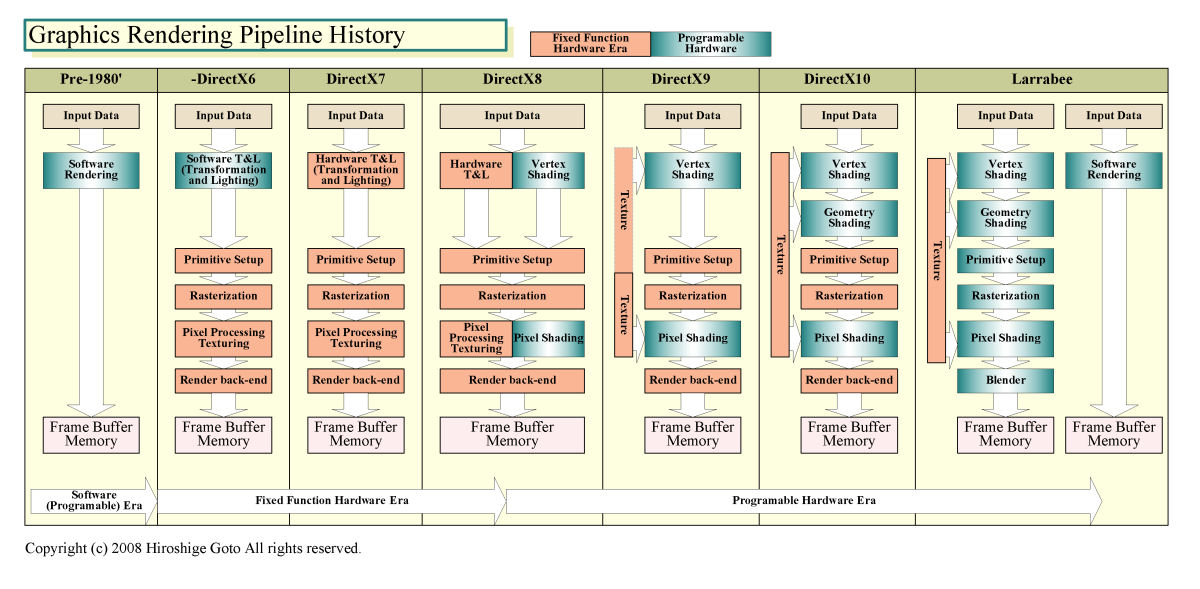
일반적인 GPU와 비교했을 때 Larrabee 파이프라인의 최대 특징은 ,고정 하드웨어(Fixed Function Hardware)를 가능한 한 배제하고,거의 풀 프로그램 가능 야채 프로세서를 만들어 냈던 것이다.현재의 GPU는 ,정점 정보를 픽셀에 변환하기 까지의,프리미티브 세트 업/라스타라이제숀은 ,고정 기능 하드웨어로 처리하고 있다.또,텍스쳐 필터링등을 행한 전용 프로세서나 ,칼라나 Z 처리를 행한 렌다박엔도,또는 ROP(Raster Operation Processor)라고 불리는 고정 하드웨어도 구비한다.
Larrabee로는 ,이 중 텍스쳐 관련의 전용 회로는 구비하지만 그 밖의 고정 기능 유닛은 대부분 없앴다.고정 기능 유닛으로 실행하고 있던 처리는 프로그램 가능 프로세서에서 소프트웨어 처리를 행한다.일반적인 GPU 것보다 훨씬 소프트웨어화가 심화되고 있는 것이 Larrabee이다.
이것은 Microsoft가 DirectX 10 이후의 하드웨어의 동향으로서 고찰하고 있던 방향과 일치한다.Microsoft는 서서히 고정 기능 하드웨어가 프로그램 가능 프로세서로의 소프트웨어에 옮겨지고 가는 경향에 있다고 보고 있다.Microsoft 자신은 효율성을 고려한 경우 어디까지 옮겨질지는 불명하다로 하고 있다.Intel은 단숨에 대부분의 파트를 프로그램 가능화 했다.일반적인 GPU 것보다 플렉시블한 하드웨어인 만큼 효율성이 있는 것이 된다.
 |
| 세대마다의 그래픽스 렌더링 파이프라인의 변천 PDF 판은 여기 |
●GPU와는 다른 프로그래밍 모델
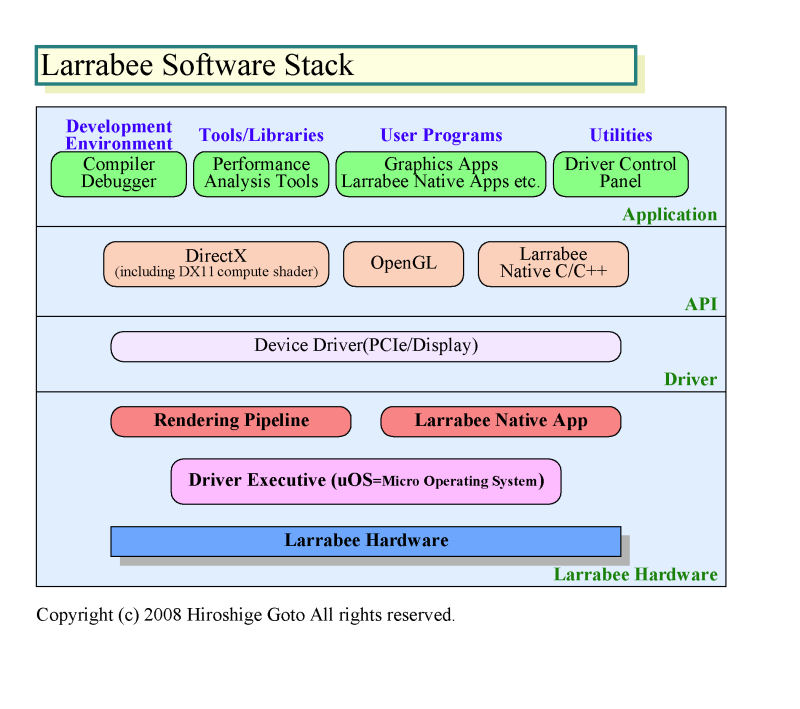
Larrabee로는 ,소프트웨어 스택의 구조도 종래의 GPU와 다르다.대부분의 GPU로는 네이티브 명령 세트에의 컴파일을 하고 대부분의 소프트웨어 처리를 호스트 CPU에서 행한다.그것에 대해 Larrabee는 자체 내에서 마이크로 OS가 실행되고 종래의 GPU라면 호스트 CPU 상의 드라이버로 행할 것을 Larrabee에서 행한다.
이 것도 이 후의 GPU의 방향성과 일치하고 있다.AMD는 이미 R600 세대로부터 범용적인 마이크로 컨트롤러를 GPU에 탑재하고 드라이버의 처리의 일부를 GPU 쪽으로 옮겼다.NVIDIA도「GPU 쪽에 드라이버를 처리하게 하는 것은 이 후의 이야기이다」(David B. Kirk(데이비드 커크)씨(Chief Scientist))와 ,동일한 방향을 생각하고 있는 것을 시사하고 있다.이 들보다 프로그램 가능 Larrabee는 동향을 미리 받아들일 필요가 있다고도 말할 수 있다.
Larrabee는 ,프로그래밍 모델의 측면도 프로그램 가능 GPU와 크게 다른다.그 것은「Single Program, Multiple Data(SPMD)」모델 이외의 프로그래밍 모델을 준비한 점이다.
GPU의 SPMD(Single Program, Multiple Data)모델으로는 ,1 데이터에 대한 프로그램을 쓰면 ,프로그램이 자동적으로 전개되고,SIMD 하드웨어상에서 멀티 스레드 실행된다.예를 들면,1 픽셀을 대우한 쉐이더 프로그램을 쓰면 자동적으로 100만도트의 픽셀에 대해 실행된다.프로그램 쪽에서는 GPU 하드웨어의 벡터 장을 의식할 필요가 없다.런 타임 소프트웨어(드라이버)가 SPMD 모델로의 SIMD의 제어를 행한다.GPU로는 그래픽스 이외의 범용 어플리케이션도 SPMD 모델로 프로그램한 수법이 일반적이다.
그것에 대해,범용의 CPU로는 SIMD 하드웨어에 직접 액세스할 수 있도록 하는 것이 일반적이다.예를 들면,x86계 CPU로는 SSE등의 SIMD 명령으로 SIMD 하드웨어를 직접 사용하는 것을 할 수 있다.Larrabee로는 「Larrabee Native C/C++」를 통하여 16 way의 SIMD를 직접 사용할 수 있다.바꾸어 말하면,벡터 장이 노출하고 있다.Intel은 Larrabee의 네이티브 ISA를 공개한다고는 말하고 있지 않지만 SPMD 이외의 프로그래밍 모델을 제공한 점은 크게 다른다.
Larrabee로 범용 어플리케이션을 프로그램한 경우에 16way SIMD를 반드시 명시적으로 프로그램하지 않으면 안되지 않냐라고 하면 그렇지도 않다.C/C++이외에 범용 컴퓨팅을 SPMD 모델로 실현한 길도 준비한다.예를 들면,DirectX 11로 도입된 범용 컴퓨팅 지향 쉐이더 스테이지「DirectX 11 Compute Shader」을 서포트한다고 말한다.
 |
| Larrabee의 소프트웨어 스택 PDF 판은 여기 |
'컴퓨터 / IT' 카테고리의 다른 글
| AMD Radeon HD 4870 X2 (0) | 2008.08.12 |
|---|---|
| Nehalem의 제품명은 "Core i7" (0) | 2008.08.11 |
| WD 320GB와 640GB의 성능 (0) | 2008.07.26 |
| 같은 하드 다른 성능 (0) | 2008.07.24 |
| 메이플스토리와 비스타 (11) | 2008.07.22 |